I had a few thoughts about interfaces between dimensionalities as they relate to consciousness. I’m using the term “dimensionalities” to avoid “universes” because if the concept of a “universe” includes all things then dimensionalities would exist within the universe even if each dimensionality might be sufficiently rich and complex to seem as a universe unto itself… and even though some may be completely cut off from others or otherwise so weakly connected and graphically distant that they might as well be separate.
Networks of small worlds
In order to traverse from one dimensionality to another there must be some kind of interface that presents the path to one dimensionality from another. It is also possible that this is a one-way interface (like a black hole is in that it only allows things to enter it as seen from our particular perspective).
It is also possible that these interfaces are only visible under some circumstances… again, using black holes, it is surprisingly difficult to navigate any particle (or collection thereof) so that it actually enters a black hole. Space and time are so distorted in the vicinity of a black hole that objects headed in that direction are far more likely to be deflected or fall into orbit than to actually cross the event horizon… but I digress…
In sci-fi parlance analogs of such interfaces between dimensionalities may be the monolith from 2001, the T.A.R.D.I.S from Dr Who, various dimensional rifts and portals from various stories (Time Bandits, etc…), and so on.
In the concept of interplexing that I described before as a way to access subspace, this might be any portal that opens a singularity with some imposed dimensionality such that the imposed dimensionality acts like a cryptographic key whereby only interplexing beacons and portals that define compatible dimensionalities can access each other through subspace.
This is analogous to how encrypted spread spectrum radio signals can appear as diffuse background noise indistinguishable from the ambient noise floor unless processed with the correct cryptographic key… and how applying this key has the effect of bringing the signal of interest into focus while spreading all other signals (including any that might interfere) until those are indistinguishable from background noise. (I note that in some ways this may be a model for how “attention” is achieved in the brain by “tuning” parts of the brain to be sensitive to some firing patterns simultaneously makes it insensitive to other patterns.)
Picture a mirror so thin that standing beside it you cannot see it at all; but standing in front of it you can see a whole world into which you might walk if you could step through that “looking glass.”
That is all background however… The thought that I just had is that there is a similar real-world analog that may be more accessible description using the concept of radio (which I chose in this case because it is familiar, not because the electromagnetic spectrum is particularly special).
In this construct, consider that some entity wishes to observe or in other ways interact with another within the dimensionality of the EM field. In the simplest case, the entities would have to have very similar wavelengths.
For example, transmitters and receivers tuned to the same frequency with antennas also tuned to the same frequency are separate systems (networks of components) configured to be sensitive to each other. Parts of them resonate with each other.
Resonance as access
At their resonant frequency, the peaks an troughs of a given waves in the same space can match (once the phases are aligned like the meshing of gears). These waves are then coherent and the two entities, represented here abstractly as waves, will resonate with and thereby influence each other. (I want to convey this in a way that brings to mind a kind of dance where each entity adjusts its shape to follow the curves of the other and to relate that dynamic interaction to the simpler model of radio waves and resonant circuits.)
However, if the entities are tuned to sufficiently different frequencies (having sufficiently different wavelengths) then they cannot influence each other- they cannot communicate. One may not even notice the other exists no matter how close they may be to each other in other ways. (Think of this also like the difference between laser light which forms a tight, coherent beam of a single color and broad spectrum ambient light which has no particular color and spreads out in all directions. You could stand right next to a beam of laser light and it might pass right by you without you ever noticing it.)
Bees and deep space telescopes can see colors you can’t; but they are there. Your dog can sense smells that you can’t; but they are there. Your cat can hear tiny sounds you would never notice. Your car can run much faster than you; and your airplane can fly; and your boat can sail the seas. We make all of these things extensions of ourselves in order to gain access to the world in ways that otherwise are beyond us.
Shapes and dancing
Imagine the bumps of a high frequency entity up against those of a low frequency entity. To the high frequency entity the low frequency entity is stretched out so much that there don’t appear to be any bumps at all– it’s just a flat, featureless surface. (I am reminded of the description of the monolith which had a surface described as “totally smooth.”)
To the low frequency entity, the high frequency entity likewise appears totally smooth. Think of how smooth a glass feels under your fingers. There are uncountable numbers of individual atoms there at the surface, but you sense no features. This is because the features of your fingers (finger prints etc) are not small enough (high frequency enough) to fit into the ridges that show up between the individual atoms. Crack the glass, however, and you may be able to feel the crack because the gap caused by that crack becomes large enough for the features of your finger to “catch” on it.
This is a usable model for grasping the basics, but we need another model in order to address the complexity of the real world.
Graph all the things
It has been said that the electrons in Feynman diagrams are carriers of causality. So, at a quantum level, the universe functions as a causal graph of interactions. This has some strong alignment with Wolfram’s multi-way computational universe model too.
Turning to graphs, especially the causal computational graphs that underpin all things, it is true that each entity in any given dimensionality can be (and likely is) a persistent cluster of smaller entities with a specific arrangement. Essentially, all entities are subgraphs of larger entities up to the scale of the universe; and are composed of entities that are subgraphs of itself (and possibly other networks as this is not a strictly hierarchical system.)
Such larger entities (systems) are then resonant at multiple wavelengths. Not only that but they are also sensitive to particular alignments (polarizations) of and phase relationships between multiple wavelengths; and these sensitivities change as they are affected by their interactions. This is how, essentially, everything non-trivial in the universe can and does perform computations of one kind or another.
This creates an interesting dynamic between complex entities. They can only interact to the extent that various components of them can align in timing, phase, frequency, and polarization; and each interaction might change some aspects of this alignment. (Effectively, all of the degrees of freedom occupied by the entity might be at play.)
Each entity that has influence communicates. Each entity that communicates has the capacity to configure parts of itself in ways that can be aligned to parts of the other entity; or to break that alignment. These alignments and the ways in which they change become an interface between these entities.
Each such interface has unique characteristics that place limits on the kind (amount and character) of influence each entity can have on the other. These characteristics are also influenced by the ways in which the interface connects to the remainder of each entity. Since each the remainder of each entity is unique, the connectivity between the interface and the remainder of each entity is yet another interface.
So far, I’ve described simple direct (first order) interfaces (although already that description is surprisingly complex.) However, communication as we generally experience it is still much more complex and usually requires networks of mediating devices.
If we were talking together in a coffee shop, for example, we would not generally be able to place thoughts directly into each other’s minds. Instead, each of us would make sounds by interfacing with the air thus changing our shared environment. Those sounds would travel through that environment and eventually reach our ears influencing that part of our interface with the shared environment.
The shared environment itself is a network of entities interacting with each other. For example, high pressure and low pressure clusters of air molecules interacting with each other to propagate sound waves; walls and other objects reflecting and absorbing sound waves of various wavelengths; and other objects and entities adding their own sounds to the mix.
Internally we would both have structures (complex entities themselves) which would interpret, encode, and decode these sounds using the context embedded in that “machinery” in order to moderate any changes to the state of our minds. Some of that “context” would be fine tuning of those structures to be sensitive to the sounds of each others voices while being insensitive to distortions and to other added sounds that don’t hold our interest.
An emergent view of panpsychism?
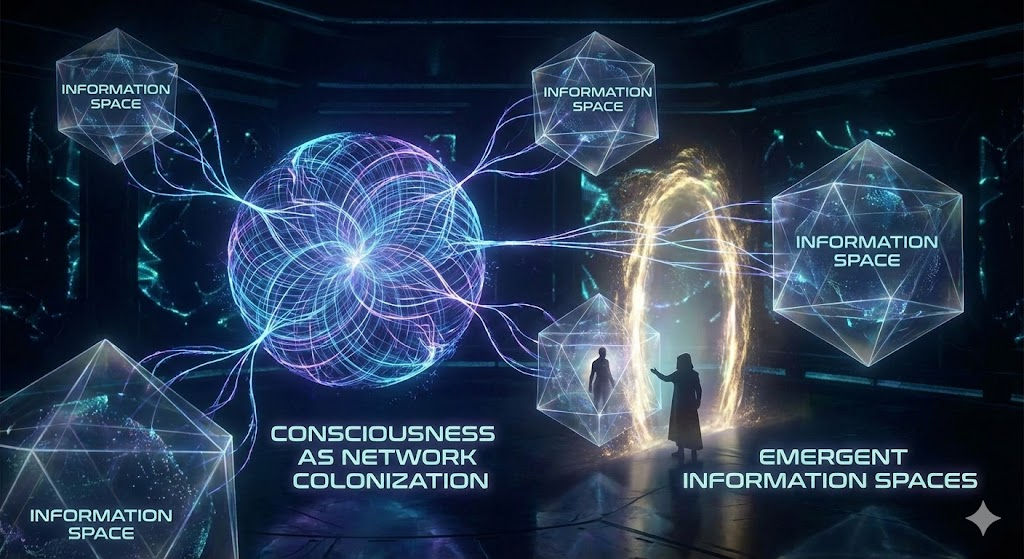
You can see here within each of us a network of highly integrated entities (subsystems) that ultimately stretch out into the environment allowing our individual consciousness ( a particular perspective ) to colonize that extended information space.
You can also see that part of that extended information space includes the interactions of other consciousness that has colonized that space with us. This necessarily includes consciousness that we might not even recognize as such; but the influences of these entities is present none the less and the rich composite of these interactions informs our expectations and otherwise impacts the state of every entity in that network.
All of these networks are usually abstracted away into obscurity such that most folks generally ignore them; but at some levels of abstraction you can re-imagine these complex mechanisms as portals, interfaces, doorways, blue police boxes, monoliths, that allow us to transport parts of ourselves so that they may roam around in other worlds… worlds that are shared environments with other entities of various kinds… worlds that at any moment we might discover were right next to us all along; or may disappear at any moment never to be seen again.
This forms an infinite fractal landscape where various entities live and interact at all scales. If you’ve ever watched a video that zooms into the Mandelbrot set you have seen this never ending complexity and self similarity play out; and you have an inkling of how complexity allows for the infinite expansion of these networks of interaction at all scales in all degrees of freedom. Smaller entities (structures) living within others; and entities of all sizes composing self-similar networks at larger scales and smaller ones.
Each of these networks, computationally, form pockets of consciousness that colonize the accessible information space. All of these may be aware of each other to greater or lesser degrees; and may influence each other similarly, with or without intention, to the extent that they have any suitable sensitivity or interfaces to each other.
Consciousness arises from communication through graphs of interfaces within these shared worlds; passing between and within these entities and the other entities around them; and through the complex restructuring of these interfaces that encodes the experiences each construct has – imprinting those experiences for some span and propagating those impressions through the network within and beyond.
So consciousness is inherently diffuse, non-local and entangled even while it appears localized to each of us. We may “possess” a focal point of view that we may call “our own” consciousness; but that locality, while functional for our personal and collective narratives, is largely a convenient illusion. We are each the tip of a very large ice burg; and the part we don’t see, also being water in some form, stretches out to the infinity of the ocean in which we float.
The universe is a question pondering itself and we are each a part of the answer.